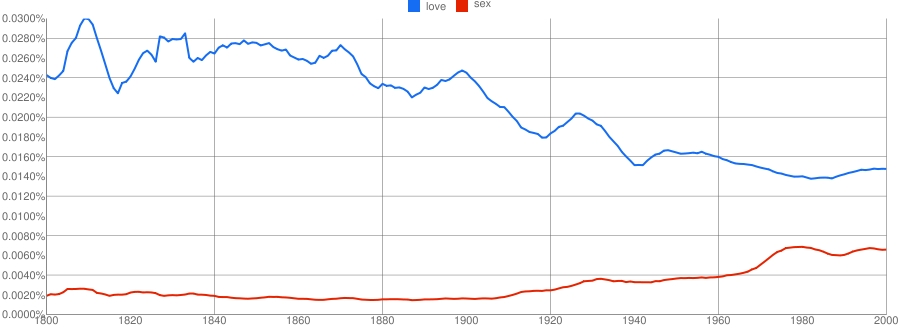
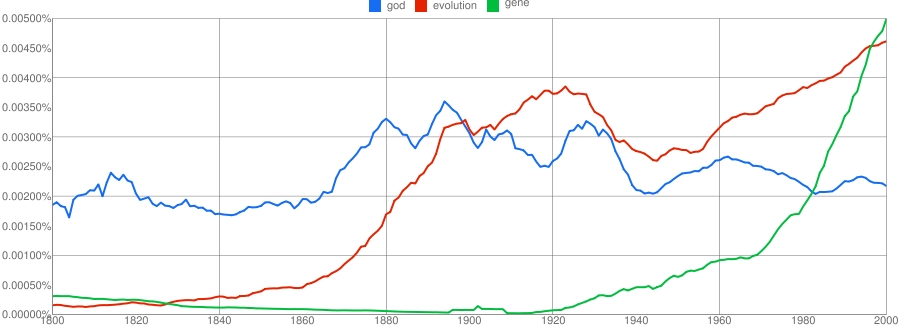
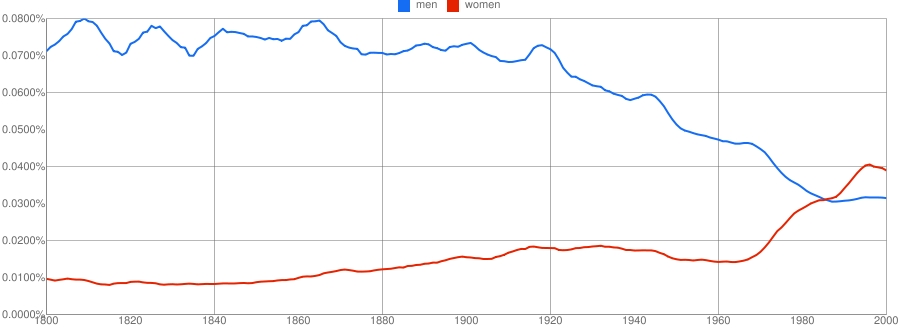
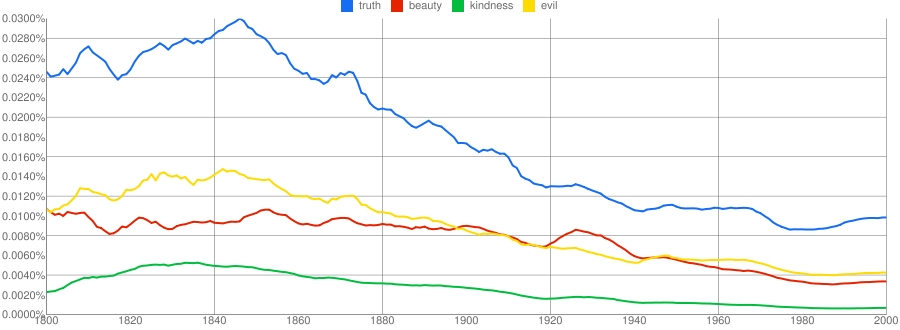
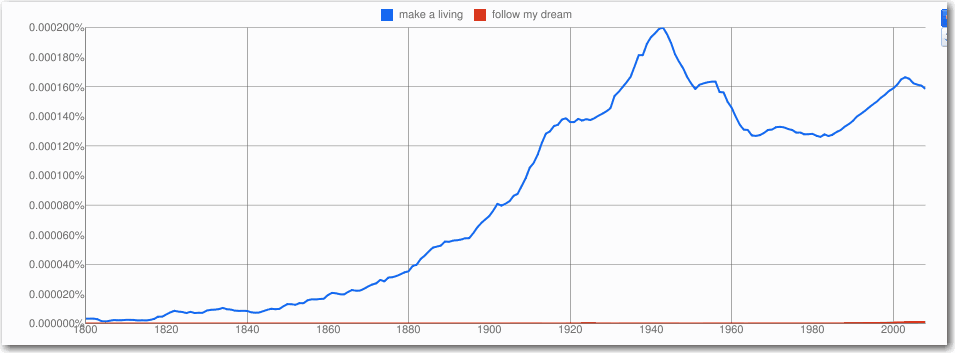
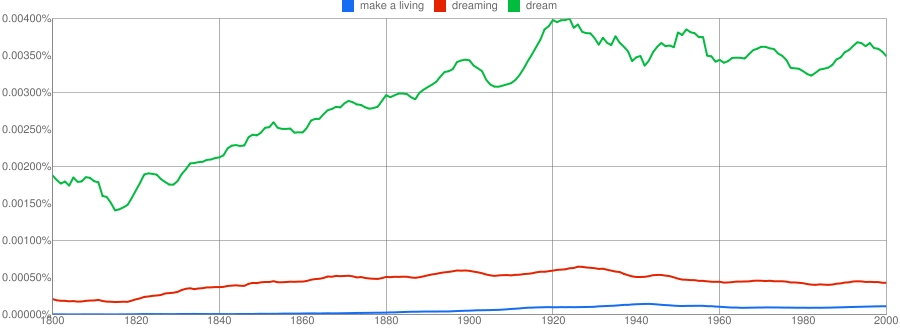
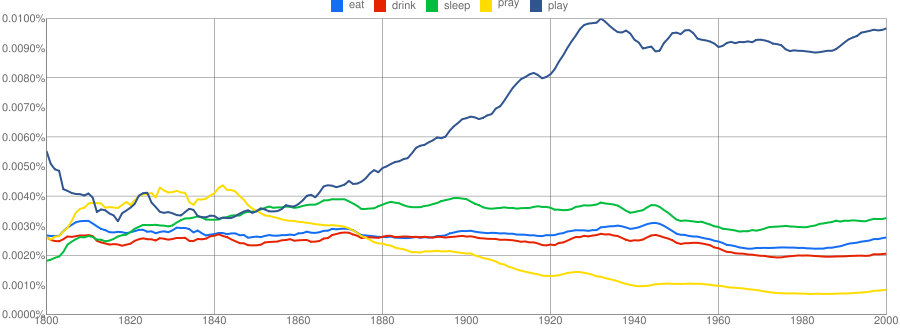
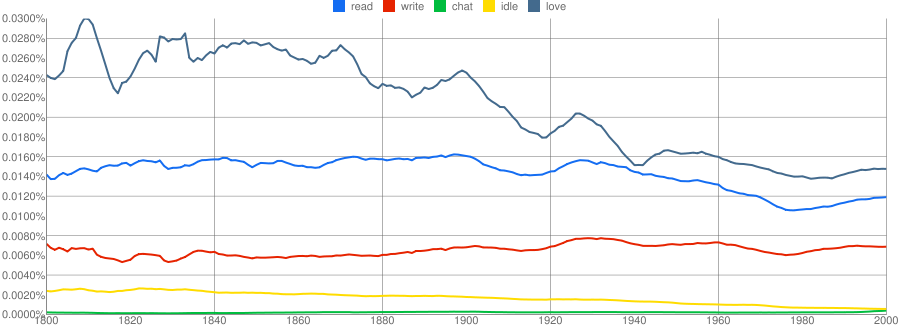
经济学家这期的报道:
http://www.economist.com/node/17730198
Culturomics
Dec 16th 2010 | from PRINT EDITION
WHEN Google began scanning books and allowing them to be searched online in 2004, publishers fretted that their literary treasure would be ransacked by internet pirates. Readers, meanwhile, revelled in the prospect of instant access to innumerable publications, some of them unavailable by other means. But Google Books is also responsible for another, quieter revolution: in the humanities.
For centuries, researchers interested in tracking cultural and linguistic trends were resigned to the laborious process of perusing volumes one by one. A single person, or indeed a team of people, can read only so many books. Large-scale number-crunching seemed an impossible task. Now, though, Jean-Baptiste Michel, of Harvard University, and his colleagues have used Google Books to do just that. They report their first results in this week’s Science.
So far Google has managed to digitise 15m of the estimated 130m titles printed since Johannes Gutenberg perfected the press in the 15th century. Dr Michel’s team whittled this down to just over 5m volumes for which reasonably accurate bibliographic data, in particular the date and place of publication, are available. They chose to focus mainly on English texts between 1800 and 2000, but also included some French, Spanish, German, Russian, Chinese and Hebrew ones.
That yielded a corpus of over 500 billion 1-grams, as Dr Michel calls a string of characters uninterrupted by a space. These include words, acronyms, numbers and dates, as well as typos (“becasue”) or misspellings (“abberation”). He also looked at combinations of 1-grams, from 2-grams (“The Economist”) to 5-grams (“the United States of America”). To minimise the risk of including random concatenations of words, rare spellings or mistakes, any word or expression had to appear in the corpus at least 40 times to merit inclusion in the final, chronologically ordered set.
At this point, the number-crunching could begin in earnest. Dr Michel first used his data to estimate the total number of words in the English language. To do this, he and his team took a random sample from the corpus, checked what proportion were non-words and extrapolated that to the whole lot. He puts the figure at a smidgen above 1m.
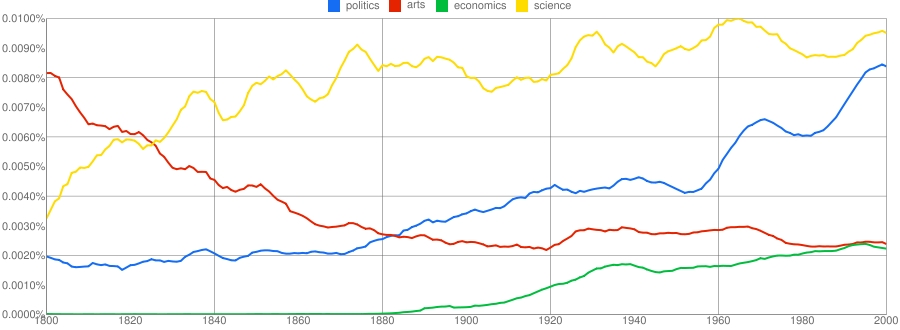
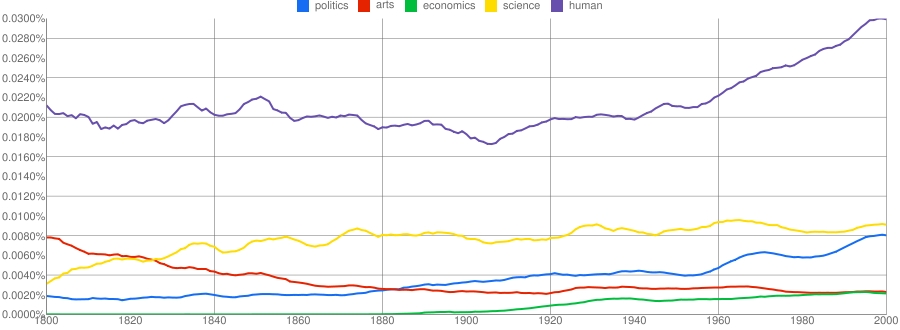
On their reckoning, even the most authoritative lexical repository, the “Oxford English Dictionary”, underrepresents this total by a factor of two. Also, after hardly budging in the first half of the 20th century, the English vocabulary expanded at a rate of 8,500 words a year in the second half, leading to a 70% increase in its size since 1950 (see chart).
Amusingly, Dr Michel found that some words added to the “American Heritage Dictionary” in 2000, like “gypseous” or “amplidyne”, had been in widespread use a century earlier. What is more, by the time they did make it into the dictionary, they were becoming obsolete.
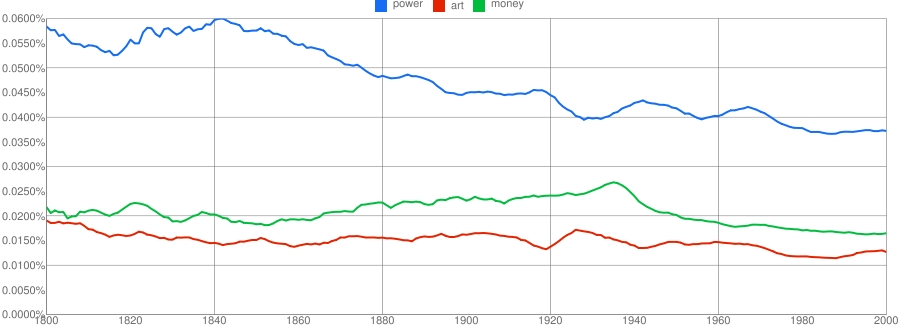
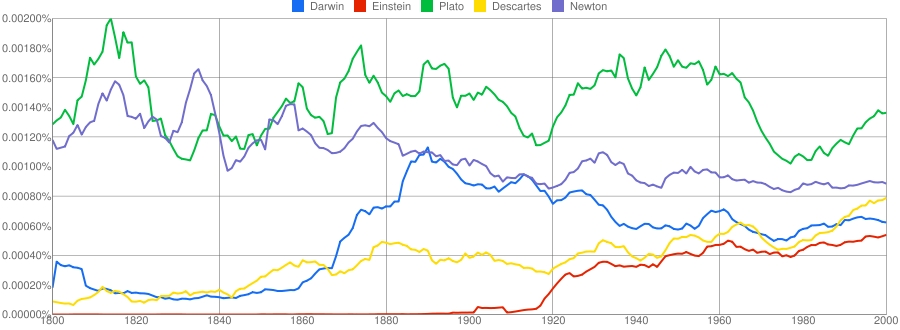
The researchers did not confine themselves to poking fun at lexicographers, though. They also looked at a range of cultural trends, such as how long it takes innovations to impinge on the popular consciousness (which is happening ever more quickly), the age at which celebrities become famous (which is dropping, albeit at the expense of ultimately shorter spells in the limelight), as well as many other more or less frivolous trends.
Clearly, books do not exhaust the whole of human culture. In recent decades their relative importance has waned. Nor are the books Google has already chosen to scan necessarily a representative sample of literature across the ages. This means that any findings based on them ought to be treated with caution.
Still, Dr Michel and his team hope that their approach will spur a more rigorous, quantitative approach to the study of human culture. In fact, their paper doubles as a manifesto for a new discipline. They dub it “culturomics”, making them the first clutch of culturomists. More are sure to follow—whether or not this particular, clunking neologism survives.